Kampf mit dem Wetter
Liebe Datenspender:innen, etwa seit Mitte Dezember letzten Jahres sahen wir bis Ende Februar einen deutlichen Rückgang der Zahl der bestätigten COVID-19-Fälle in Deutschland. Gleichzeitig beobachten wir, dass der Fiebermonitor – ungefähr seit dem Jahreswechsel – von den COVID-19-Fallzahlen abweicht. In diesem Beitrag versuchen wir zu erklären, was in den vergangenen Wochen und Monaten passiert ist, wie es zu diesem Unterschied zwischen den beiden Kurven kommen konnte – und welche Schlüsse wir daraus gezogen haben. Das Ergebnis dieser Überlegungen wollen wir euch in unserem aktualisierten Algorithmus vorstellen.
Was ist passiert?
Kurz zur Erinnerung: Der Datenspende-Algorithmus zur Fieberdetektion verwendet die Daten des Ruhepulses und der täglichen Schrittanzahl von Fitness-Tracking-Geräten, um Muster zu erkennen, die für Fiebersymptome charakteristisch sind. Wir wissen, dass ein erhöhter Ruhepuls in Verbindung mit einer verminderten körperlichen Aktivität (weniger Bewegung) auf Fieber hinweisen kann. Daher ist unser Algorithmus so konzipiert, dass er für jede Person eine Baseline dieser Messgrößen ermittelt und Abweichungen davon erkennt. Wenn der Ruhepuls einer Person signifikant erhöht ist und gleichzeitig die tägliche Schrittanzahl relativ zu einem Schwellenwert, der durch die Schwankungsbreite der Messwerte definiert ist, deutlich verringert ist, wird eine Fieberdetektion ausgelöst. Der Fiebermonitor stellt die Rate der Fieberdetektionen über alle Benutzer im Zeitverlauf dar. Da Fieber eines der Kernsymptome von COVID-19 ist, waren die offiziellen Fallzahlen der primäre Bezugspunkt für unsere Fieberdetektionskurven. Das Ziel des Algorithmus unseres Datenspendeprojekts ist es jedoch, eine Schätzung der aktuellen Fieberhäufigkeit in der Bevölkerung zu liefern und nicht, die COVID-19-Fallzahlen zu replizieren. Denn Fieber kann auch durch andere Krankheiten verursacht werden, wie z.B. Grippe und Atemwegsinfektionen. Die beobachtete starke Abweichung in diesem Fall kann jedoch nicht allein durch andere Fieberursachen erklärt werden.
Die Rolle des Wetters
Im Sommer 2020 verursachte eine plötzliche Hitzewelle einen anfänglichen Abfall des Ruhepulses, gefolgt von einem starken Anstieg, während das Aktivitätsniveau aber ziemlich stabil blieb. Dies stellte eine Herausforderung für den Algorithmus dar, da die Baseline einige Wochen zuvor definiert wurde. Nach dem Abfall des Ruhepulses lagen plötzlich alle Messungen weit über der Baseline. Jetzt im Winter 2020/2021 scheint es genau umgekehrt zu sein. Nach einem plötzlichen Abfall des Ruhepulses und des Aktivitätsniveaus nach Beginn des Lockdowns und Einsetzen des kalten Wetters ist die Schrittanzahl seit Beginn des Jahres wieder allmählich gestiegen, während der Ruhepuls relativ unverändert geblieben ist. Hier ein Blick auf die Durchschnittswerte über die Zeit:

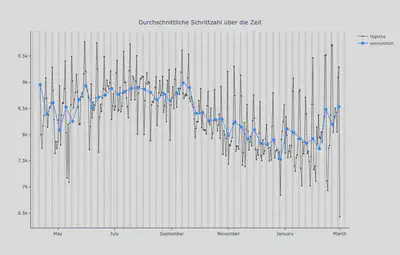
Um unsere Sommer-Anomalie zu beheben, haben wir sowohl eine Normalisierung implementiert, um abnormale Wettereffekte zu bekämpfen, als auch eine längere Baselineperiode für den Ruhepuls eingeführt. Warum der längere Zeitraum? Bei der kurzen Baseline, die insgesamt relativ stabil ist, wirken sich kurzfristige Abweichungen aufgrund externer Faktoren erheblich aus, so wie in der Abbildung oben zu sehen ist.
Was war das Problem?
In der Abbildung, die die Schrittanzahl über die Zeit zeigt, könnt Ihr deutlich ein langes Sinus-Muster erkennen, das den verschiedenen Jahreszeiten entspricht. Unsere längere Baseline funktioniert in diesem Fall nicht, da in den Wintermonaten jeder zu einer niedrigeren Schrittanzahl neigt. Die Schrittanzahl ist aber, wie oben erwähnt, einer der Schlüsselfaktoren unseres Algorithmus. Diese Veränderungen sind nicht auf Anomalien zurückzuführen, sondern auf eine deutliche saisonale Veränderung, die sich über mehrere Monate erstreckt. Wenn wir also die Schrittanzahl von dieser Woche mit der von vor drei Monaten vergleichen, werden wir wahrscheinlich eine starke Abweichung feststellen. Aber was wäre, wenn wir nur ein paar Wochen zurückblicken würden? Das würde eine genauere Vorstellung vom aktuellen Aktivitätsniveau vermitteln und kurzfristige Abweichungen davon besser erkennen lassen.
Bessere Übereinstimmung mit COVID-19-Fallzahlen
Also haben wir genau das geändert. Wir haben die Zeitspanne für die Berechnung der Baseline für die Schrittanzahl verkürzt, während wir die lange Baseline für den Ruhepuls beibehalten haben. Außerdem haben wir den Ruhepuls stärker gewichtet, da er unsere primäre Messgröße ist und unsere Detektionen dies widerspiegeln sollten. Als Ergebnis wird der Algorithmus zur Fieberdetektion nicht mehr von äußeren Bedingungen beeinflusst und stimmt jetzt viel besser mit den COVID-19-Fallzahlen überein:
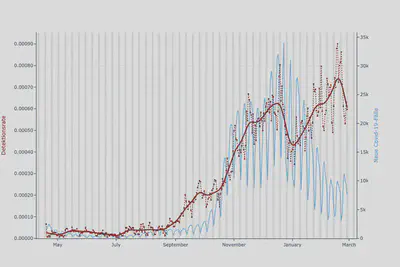
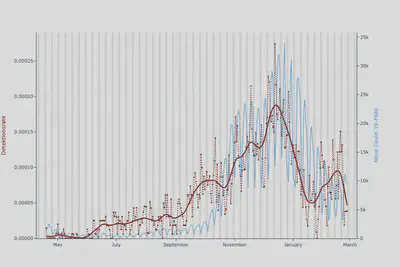
Wir verfeinern weiter
Das Projekt Datenspende ist das erste seiner Art und hat eine starke experimentelle Komponente. Das heißt: Es erfordert gelegentliche Verbesserungen der zugrunde liegenden Algorithmen. In den kommenden Wochen erwarten wir, dass weitere Modifikationen am Algorithmus notwendig sein werden, da wir unsere Methoden immer weiter verfeinern. Einige werden bemerkt haben, dass wir die einzelnen Kurven für die Bundesländer entfernt haben. Wir haben diesen Schritt gemacht, weil wir uns zuerst auf die Korrektur des Trends für die bundesweite Kurve konzentrieren wollten. Wir haben immer noch das Ziel, in Zukunft wieder regionale Kurven zur Verfügung zu stellen, aber wir müssen wahrscheinlich einige der bevölkerungsärmeren Bundesländer aggregieren. Der Grund: Unterhalb einer bestimmten Grenze von Spendern pro Region stellt sich die Detektionsrate als verzerrt heraus und liefert nicht das notwendige Maß an Informationen, die wir weitergeben wollen.